Table Extraction Series – Part 2: Deep Learning Approaches
Table of contents

In this second article of our Table Extraction series, we will see how to apply deep learning approaches to detect tables and decode them on document images.
You can read the first article of the Table Extraction Series herePart 1: Challenges(opens in a new tab)
Introduction Object detection applied to table detection and table decoding
R-CNN SPP-Net Fast R-CNN Faster R-CNN FPN R-FCN
YOLO (v1 to v7) SSD RetinaNet CenterNet EfficientDet
End-to-end approaches PROs and CONs of deep learning approaches
Introduction
Deep learning can be used for both table detection and table decoding.
Table detection refers to the task of localizing a table on an image or document. The algorithm used for table detection should return the coordinates of the table, usually denoted by 2 points: upper left and lower right.
The figure below shows an example of tables detected on an image with blue bounding boxes around the tables.
Figure 1: detected tables (source [3])
Table decoding refers to the task of localizing rows and columns of a table. Just like table detection, a table decoding algorithm needs to return the coordinates of each row and column. The figure below shows rows and columns detection. Cell detection is then found by the intersection of a row and a column.
Figure 2: detected rows and columns (source [4])
Both tasks of table detection and table decoding in deep learning are part of a family of tasks called “object detection.”
In most of the deep learning approaches, table detection and decoding were done by applying known object detection models on tables. So it was mainly a domain adaptation problem. But some approaches were developed specifically for table detection and table decoding. Below, we’re going to explore both.
Object detection applied to table detection and table decoding
Object detection refers to the task of localizing objects on an image. In deep learning, there are 2 main types of object detectors: one-stage object detectors and two-stages object detectors.
Two-stage object detectors
A neural network with a separate module to generate region proposals is termed a two-stage detector. These models try to find an arbitrary number of object proposals in an image during the first stage and then classify and localize them in the second.
As these systems have two separate steps, they generally take longer to generate proposals, have complicated architecture, and lack global context.
Here are some of the widely used two-stage object detectors:
R-CNN
The Region-based Convolutional Neural Network (R-CNN) was the first paper in the R-CNN family and demonstrated how CNNs can be used to immensely improve the detection performance. R-CNN use a class-agnostic region proposal module with CNNs to convert detection into classification and localization problem.
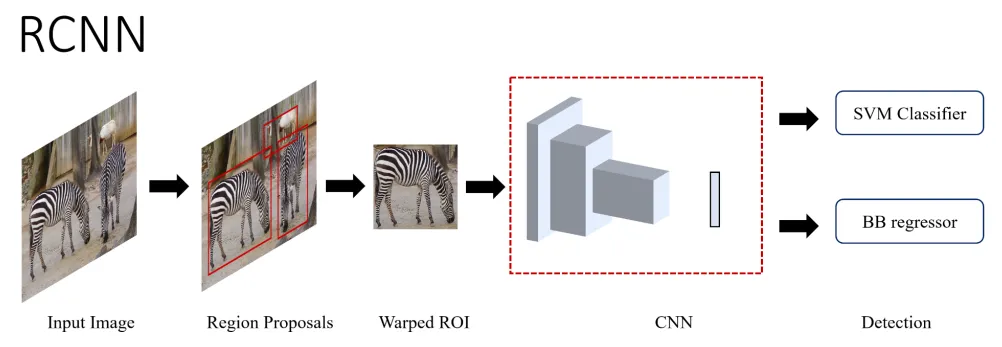
Figure 3: High-level overview of RCNN (source [1])
SPP-Net
This approach proposed the use of a Spatial Pyramid Pooling (SPP) layer to process images of arbitrary sizes or aspect ratios. Since only the fully connected part of the CNN required a fixed input, SPP-net merely shifted the convolution layers of a CNN before the region proposal module and added a pooling layer. Thereby making the network independent of size/aspect ratio and reducing the computations.
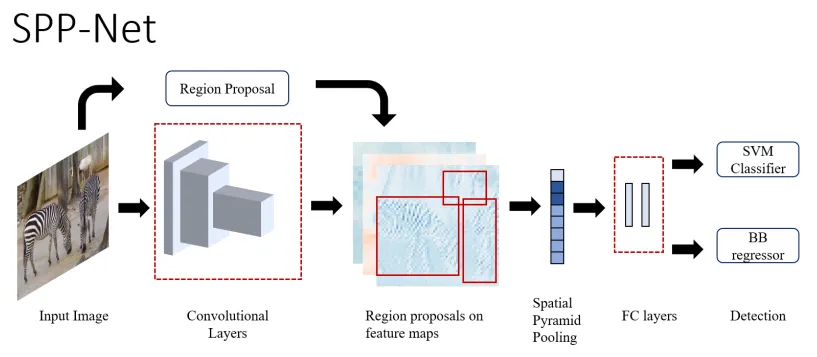
Figure 3: High-level overview of RCNN (source [1])
Fast R-CNN
One of the major issues with R-CNN/SPPNet was the need to train multiple systems separately. Fast R-CNN solved this by creating a single end-to-end trainable system. The network takes as input an image and its object proposals. The image is then passed through a set of convolution layers, and the object proposals are mapped to the obtained feature maps.
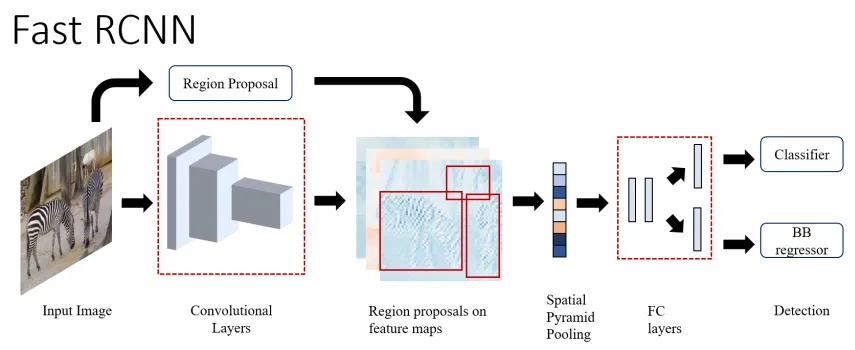
Figure 5: High-level overview of Fast RCNN (source [1])
Faster R-CNN
Even though Fast R-CNN inched closer to real-time object detection, its region proposal generation was still very slow. That’s where Faster RCNN came in. It uses a fully convoluted network as a region proposal network (RPN) that takes an arbitrary input image and outputs a set of candidate windows. Each window has an associated objectness score which determines the likelihood of an object.
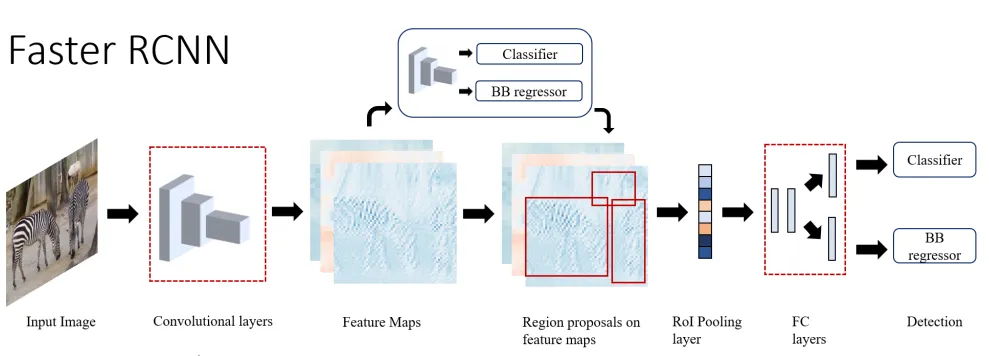
Figure 6: High-level overview of Faster RCNN (source [1])
FPN
The use of an image pyramid to obtain what we call feature pyramids (or featurized image pyramids) at multiple levels is a common method to increase the detection of small objects. Feature Pyramid Network (FPN) is used as a region proposal network (RPN) of a ResNet-101 based Faster R-CNN. It has a top-down architecture with lateral connections to build high-level semantic features at different scales.
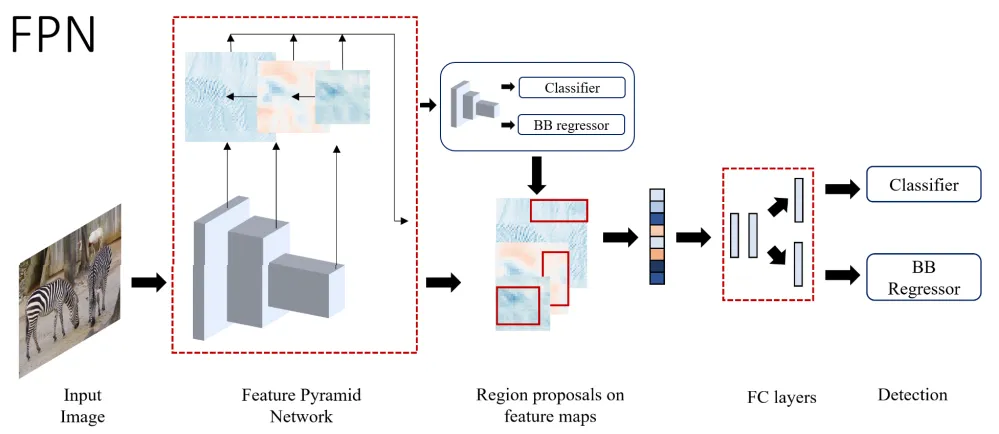
Figure 7: High-level overview of FPN (source [1])
R-FCN
The previous two-stages detectors applied resource-intensive techniques on each proposal. But the new technique called “Region-based Fully Convolutional Network (R-FCN)” proposed sharing almost all computations within the network. This decreased inference time significantly.
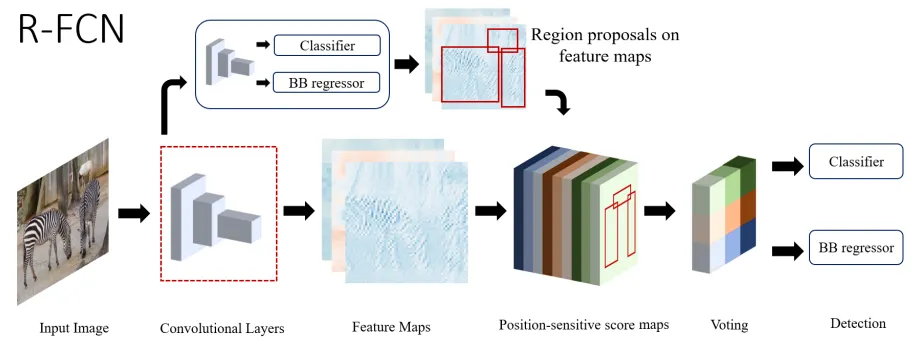
Figure 8: High-level overview of R-FCN (source [1])
One-stage object detectors
One-stage detectors classify and localize semantic objects in a single shot using dense sampling. They use predefined boxes/key points of various scales and aspect
ratios to localize objects. These detectors outperform two-stage detectors in real-time performance and simpler design.
Here are some of the widely used one-stage object detectors:
YOLO (v1 to v7)
YOLO stands for “You Only Look Once.” This architecture reframed the problem of object detection as a regression problem, directly predicting the image pixels as objects and their bounding box attributes. In YOLO, the input image is divided into a S x S grid, and the cell where the object’s center falls is responsible for detecting it.
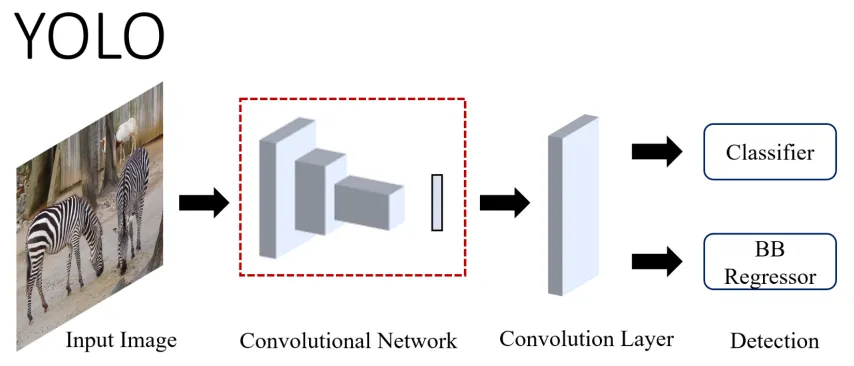
Figure 9: High-level overview of YOLO (source [1])
SSD
Single Shot MultiBox Detector (SSD) was the first single-stage detector that matched the accuracy of contemporary two-stages detectors like Faster R-CNN, while maintaining real-time speed. SSD was built on VGG-16, with additional auxiliary structures to improve performance.
These auxiliary convolution layers, added to the end of the model, decrease progressively in size. SSD detects smaller objects earlier in the network when the image features are not too crude, while the deeper layers are responsible for detecting larger objects.
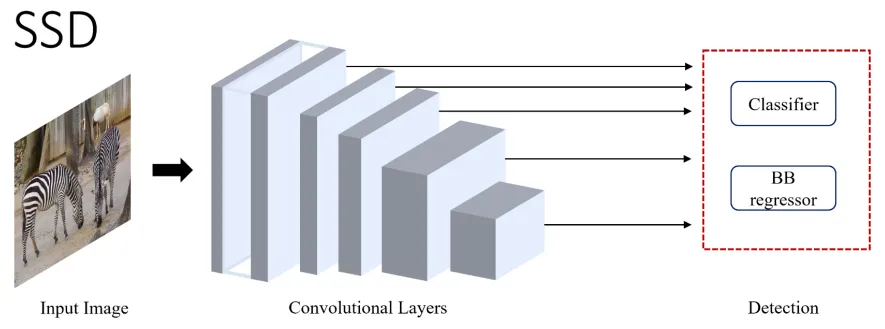
Figure 10: High-level overview of SSD (source [1])
RetinaNet
Two-stage detectors were still outperforming single-stage detectors when it came to accuracy. The reason single-stage detectors lag is the extreme foreground/background class imbalance. To address this issue, the cross-entropy loss had to be modified. RetinaNet introduced Focal loss, which reduces the loss contribution from easy examples.
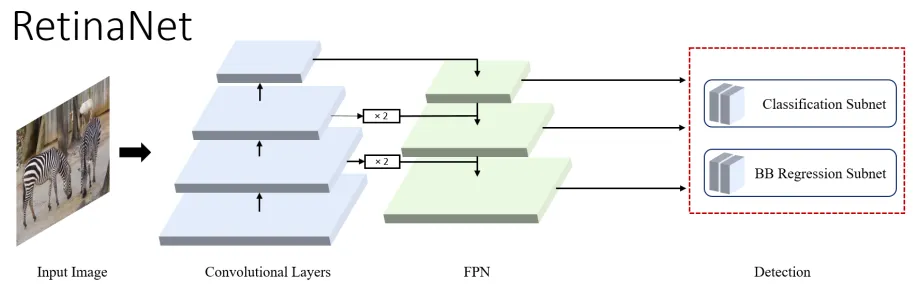
Figure 11: High-level overview of RetinaNet (source [1])
CenterNet
This architecture takes a very different approach to perform object detection. It models objects as points instead of the conventional bounding box representation. CenterNet predicts the object as a single point at the center of the bounding box. The input image is passed through the FCN that generates a heatmap, whose peaks correspond to the center of the detected object. It uses an ImageNet pretrained stacked Hourglass-101 as the feature extractor network and has 3 heads:
- heatmap head to determine the object center,
- dimension head to estimate the size of the object,
- and offset head to correct the offset of the object point.
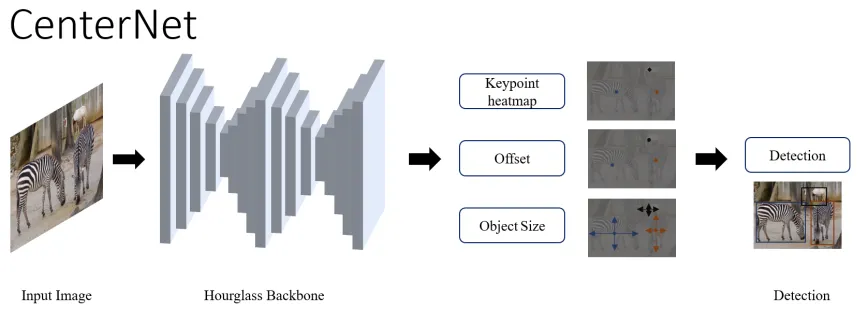
Figure 12: High-level overview of CenterNet (source [1])
EfficientDet
EfficientDet builds towards the idea of scalable detectors with higher accuracy and efficiency. It introduces efficient multi-scale features, BiFPN, and model scaling. BiFPN is a bi-directional feature pyramid network with learnable weights for cross-connection of input features at different scales. It improves on NAS-FPN, which requires heavy training and has a complex network, by removing one-input nodes and adding an extra lateral connection. This eliminates less efficient nodes and enhances high-level feature fusion.
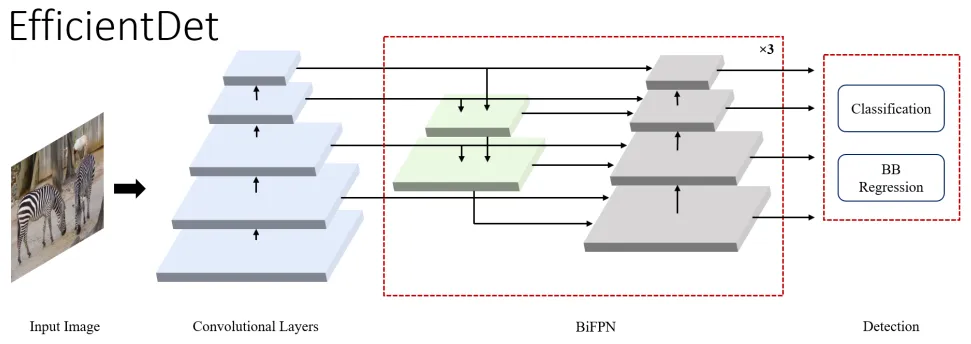
Figure 13: High-level overview of EfficientDet (source [1])
We can apply these object detectors for the two tasks: table detection and table decoding (column detection and row detection). But these tasks will be treated separately. Even if only one model is being used to detect 3 classes: full tables, columns, and rows.
Since tables are a composition of columns and rows, it would be more natural to try and combine the localization of these 3 classes in an end-to-end fashion. That’s what we’re going to explore next.
End-to-end approaches
To perform table detection and table decoding in an end-to-end fashion, the model needs to learn what makes a table and what makes a column or a row. It also needs to learn the intrinsic similarities between these elements. That’s exactly what TableNet model tried to do.
In the TableNet paper, it’s mentioned that if convolutional filters utilized to detect tables can be reinforced by column-detecting filters, then this should significantly improve the performance of the model.
The architecture of TableNet is shown below.
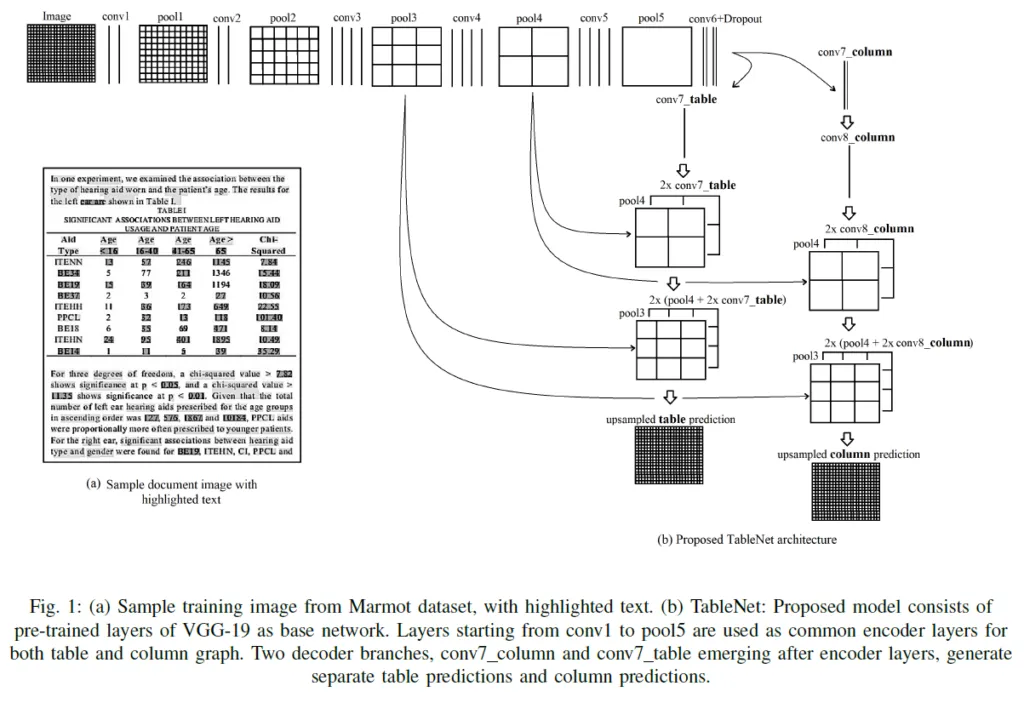
Figure 14: High-level overview of TableNet (source [2])
As we can see from the figure, there are 2 outputs of the model: one for the full table and one for the columns. But what’s interesting about this approach is that there are some shared layers between both tasks (table detection and column detection), and then there are specialized layers for each task.
What we end up getting is a set of masks that highlight regions where tables are and other masks that highlight where columns are. It should be noted that rows were omitted in TableNet, but they could be incorporated in the same manner as columns. The figure below shows the output masks.

Figure 15: TableNet output masks (source [2])
PROs and CONs of deep learning approaches
Fully deep learning approaches applied to table detection and table decoding can have a lot of advantages. But they also have some limitations.
Pros
- Very high accuracies for both table detection and table decoding. State-of-the-art models are achieving high accuracies on public datasets such as PubTables-1M.
- Can generalize on new data.
- The training process is similar to most other machine learning pipelines, which makes knowledge transfer easier.
Cons
- Most models for table detection and table decoding are very large. This makes it difficult to embed them on edge devices or inside SDKs.
- Training may require considerable resources, both in terms of data as well as in terms of computation power.
In the next and last article of the series, we’ll see in more detail the Layout Understanding approach we’re using with GdPicture.NET.
Nour, Guest Author
References
[1] Zaidi, S. S. A., Ansari, M. S., Aslam, A., Kanwal, N., Asghar, M., & Lee, B. (2021). A Survey of Modern Deep Learning-based Object Detection Models (Version 2). arXiv. https://doi.org/10.48550/ARXIV.2104.11892(opens in a new tab).
[2] Paliwal, S., D, V., Rahul, R., Sharma, M., & Vig, L. (2020). TableNet: Deep Learning model for end-to-end Table detection and Tabular data extraction from Scanned Document Images (Version 1). arXiv. https://doi.org/10.48550/ARXIV.2001.01469(opens in a new tab).
[3] Harit, G., & Bansal, A. (2012). Table detection in document images using header and trailer patterns. In Proceedings of the Eighth Indian Conference on Computer Vision, Graphics and Image Processing - ICVGIP ’12. the Eighth Indian Conference. ACM Press. https://doi.org/10.1145/2425333.2425395(opens in a new tab).
[4] Siddiqui, S. A., Fateh, I. A., Rizvi, S. T. R., Dengel, A., & Ahmed, S. (2019). DeepTabStR: Deep Learning based Table Structure Recognition. In 2019 International Conference on Document Analysis and Recognition (ICDAR). 2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE. https://doi.org/10.1109/icdar.2019.00226(opens in a new tab).


