Introduction to the New Key-Value Pair Data Extractor for the OCR Engine
Table of contents
We just released our first implementation of a key-value pair data extractor in the OCR engine for intelligent document understanding and processing. Let’s have a closer look at it.
Key-value pair and intelligent document understanding
Key-Value Pair (KVP) Intelligent Document Processing (IDP)
There are only benefits… …for all industries
Key-value pair extraction in GdPicture.NET
Key-value pair and intelligent document understanding
Key-value pair extraction is at the heart of document processing(opens in a new tab).To understand how it works and what it brings, it’s necessary to explain the concepts behind the words. We will then see why it’s so important for companies and organizations of all industries.
Definitions
Key-Value Pair (KVP)
KVPs are two related data items, a key, and a value. The key defines the data and is fixed, and the value is variable and describes the key.
Example:First name (key) : Elodie (value)
Depending on the type of document, the key-value pair fields are different. For instance, the ones on an invoice will be different than the ones on a survey or a government form.
Key-value pair fields for invoices can be:
- Invoice Number
- Date
- Total Amounts
- Taxes
For government forms you can have:
- Social Security number
- Date of birth
- Personal address
It’s easy to get key-value pairs from structured documents like excel files because the values are all named.
Intelligent Document Processing (IDP)
Intelligent Document Processing(opens in a new tab) extracts data from unstructured and semi-structured documents using OCR and artificial intelligence technologies.
Any document that does not have a pre-defined data model or is not organized in a pre-defined manner has unstructured data, which represents about 90% of all documents generated.
For these documents, you will need a tool to retrieve the information.
Benefits and areas of use
There are only benefits…
There are many ways where KVP can help. For instance, it is useful for:
- enhanced document indexing,
- automatic labellisation,
- automatic removal of sensitive information (helps with redaction),
- invoice processing,
- and more.
And as with all automation tools, the global benefits are always:
- less errors,
- quicker workflows,
- compliance.
...for all industries
The list of use cases for KVP extraction is endless and most, if not all industries can benefit from implementing it into their processes. Once the information is extracted, it's easy to repurpose it where needed. Organizations that manage paper-based forms scanned to PDF, native PDFs filled with form fields are the obvious candidates. We usually find KVP extraction needs in the following industries:
- Banking and finance
- Insurances
- Healthcare
- Government and public agencies
- HR and financial services for all industries
Key-value pair extraction in GdPicture.NET
OCR engines usually rely on different approaches:
- heuristic,
- mathematical,
- machine learning.
For the GdPicture.NET OCR(opens in a new tab) (and KVP) engine, we use the three approaches. But let's look at the traditional approaches first.
Traditional approaches
Traditional OCR
Traditional OCR based on heuristics is a mature extraction technology that works for simple use cases.A KVP engine can rely on this type of OCR to extract data.In this case, the most important limitation of the traditional OCR approach is the need to use a template for each document type. If the document is structured, it works very well. However, for unstructured or semi-structured documents it is much more complex.
Also, with this approach, we will encounter the same limitations that we find with traditional OCR engines, that have difficulties recognizing text in the following contexts:
- colored backgrounds,
- glaring,
- skew,
- text in tables and graphics,
- handwritten text.
It will also be difficult to scale a solution that relies on traditional OCR only.
Deep Learning
Machine and Deep Learning OCR use AI technologies to mitigate the traditional OCR limitations.
Deep learning can be applied to Key-Value pair extraction. Several techniques have been proposed in the literature to try and tackle this problem.
To extract key-value pairs, there should be a step where all the text on an image or PDF document needs to be extracted. So we can look at this data extraction task as a composition of 2 subtasks :
- Extracting unstructured information or text. Which is usually done by using some sort of an OCR engine.
- Making sense of this unstructured information by composing links between different parts of the extracted text.
For both of these 2 subtasks, deep learning could be used.
We have covered in previous articles(opens in a new tab), how deep learning can be used for the first subtask.
For the second subtask, which is about making sense of the extracted text, several approaches have been proposed. These approaches differ in terms of the type of data they take into account for inferring the relationships between different parts of the extracted text like it’s shown in the figure below from [1].
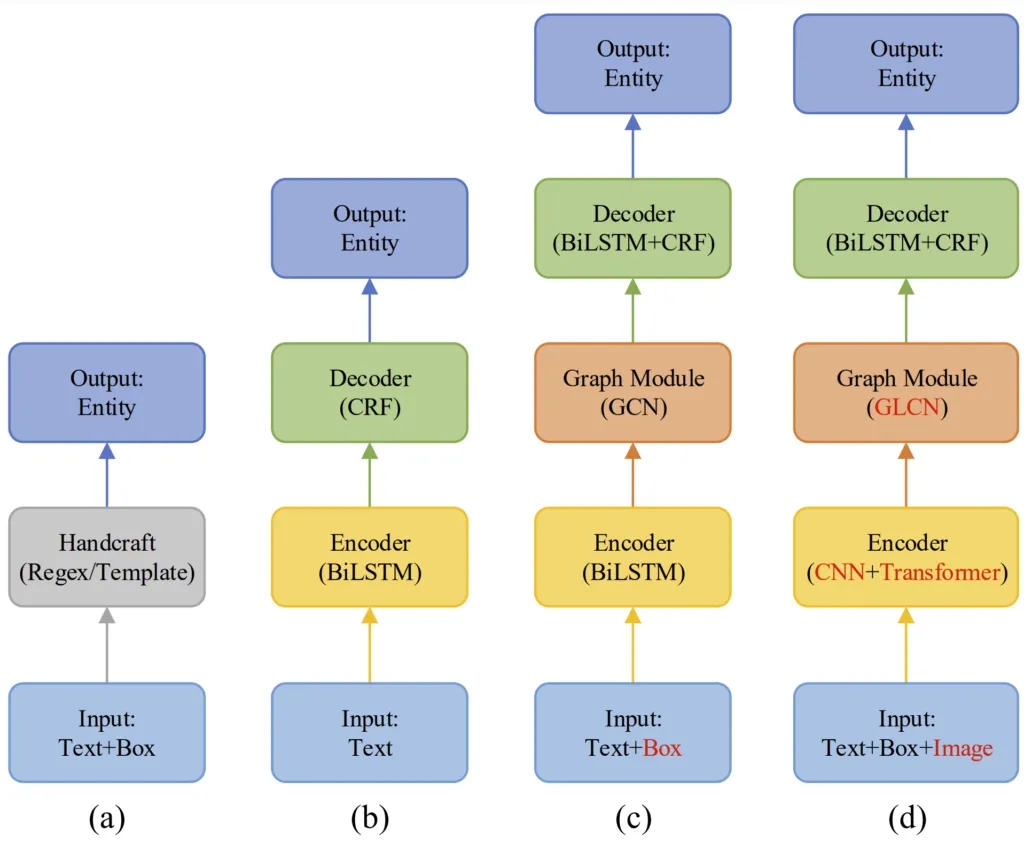
These deep learning approaches are usually a combination of different techniques such as convolutional neural networks, long short-term memory layers, transformers, and graph neural networks.
Our approach
The KVP extract engine is fully part of the GdPicture.NET OCR engine and like the other OCR technologies (MICR, MRZ, OMR, contextual OCR, and more(opens in a new tab)), it benefits from a hybrid approach that includes heuristics, mathematics, and ML capabilities. We use an adaptive layout understanding and the same underlying elements techniques as NLP technologies.
The GdPicture.NET engine automatically adapts to the document and searches for the right approach, making the best use of resources available.
This approach allows us to have excellent results on the usual weaknesses of traditional OCR and pure Machine Learning engines, especially with:
- Text recognition in documents with lots of noise thanks to adaptive despeckling,
- Dotted lines: ML engines often fail on recognizing them,
- Touching & broken characters, thanks to character segmentation,
- Text on colored background: we’re using thresholding and image segmentation to make the image easier to analyze by converting an image from color or grayscale into a binary image,
- Underlined text,
- Skewed text,
- Text in graphics and tables.
How to use
To use our engine to extract useful information from forms such as invoices, you can follow these steps:
- Create a GdPictureOCR(opens in a new tab) instance and a GdPictureImaging(opens in a new tab) instance.
- Load an image(opens in a new tab) of your form using the GdPictureImaging instance.
- Run OCR on your image using the GdpictureOCR object.
- Use the method GetKeyValuePairCount(opens in a new tab)to get the number of extracted key-value pairs.
string caption = "Example: KVP/OCR"; using (GdPictureOCR gdpictureOCR = new GdPictureOCR()) { //Set up your prefered parameters for OCR. gdpictureOCR.ResourceFolder = "\GdPicture.Net 14\redist\OCR"; gdpictureOCR.EnableSkewDetection = true; if (gdpictureOCR.AddLanguage(OCRLanguage.English) == GdPictureStatus.OK) { //Set up the image you want to process. GdPictureImaging gdpictureImaging = new GdPictureImaging(); //The standard open file dialog displays to allow you to select the file. int image = gdpictureImaging.CreateGdPictureImageFromFile("");
gdpictureOCR.SetImage(image);
string ocrResultID = gdpictureOCR.RunOCR();
if (gdpictureOCR.GetStat() == GdPictureStatus.OK) { string keyValuePairsData = "";
for (int pairIdx = 0; pairIdx < gdpictureOCR.GetKeyValuePairCount(ocrResultID); pairIdx++) { if (pairIdx != 0) { keyValuePairsData += "\n"; } keyValuePairsData += "Name: " + gdpictureOCR.GetKeyValuePairKeyString(ocrResultID, pairIdx) + " | " + "Value: " + gdpictureOCR.GetKeyValuePairValueString(ocrResultID, pairIdx) + " | " + "Type: " + gdpictureOCR.GetKeyValuePairDataType(ocrResultID, pairIdx).ToString() + " | " + "Accuracy: " + Math.Round(gdpictureOCR.GetKeyValuePairConfidence(ocrResultID, pairIdx), 1).ToString() + "%"; } MessageBox.Show(keyValuePairsData, caption); } else { MessageBox.Show("The OCR process has failed with the status: " + gdpictureOCR.GetStat().ToString(), caption); } //Release the used image. gdpictureImaging.ReleaseGdPictureImage(image); } else MessageBox.Show("The AddLanguage() method has failed with the status: " + gdpictureOCR.GetStat().ToString(), caption); gdpictureOCR.ReleaseOCRResults(); }
- Then you can iterate through the pairs to get : the key, the value, the data type and the confidence level.
When you pass an image of a form like the one below:
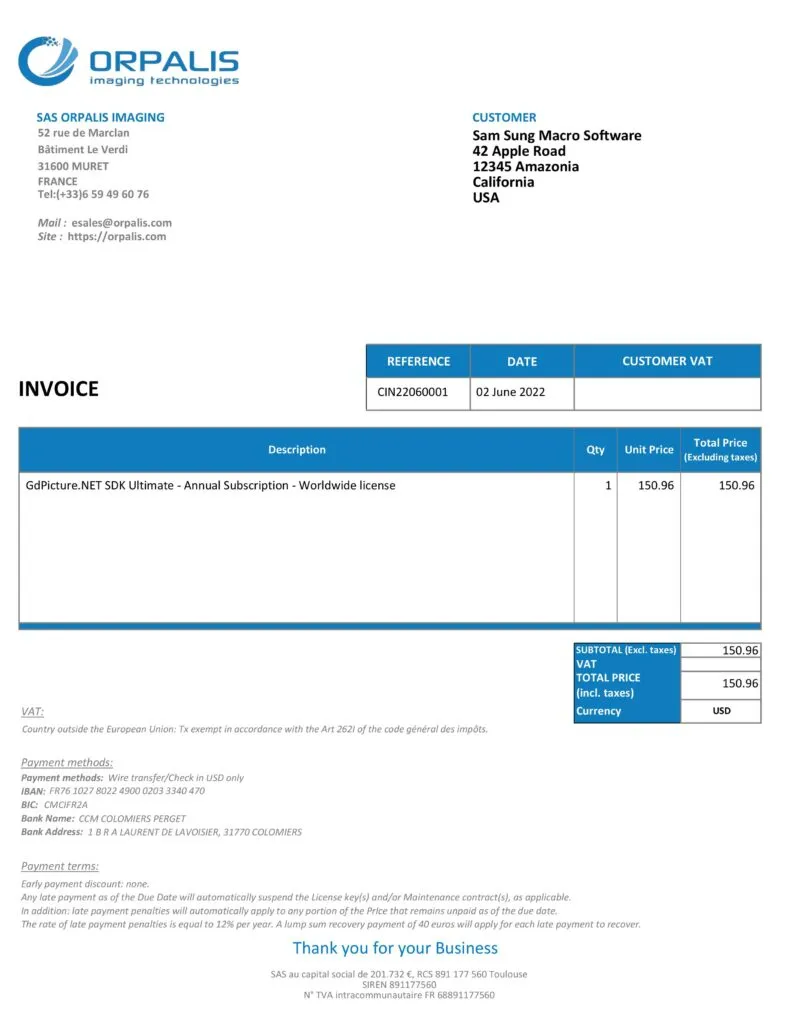
You’ll be able to extract key information such as the ones shown below:
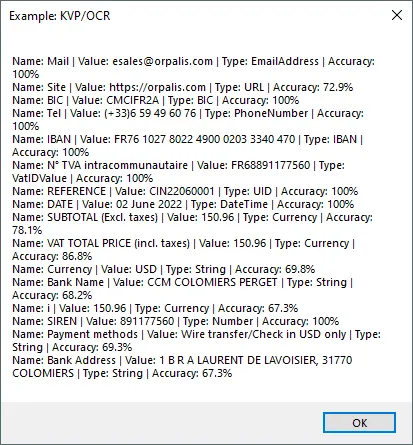
The GdPicture.NET KVP extraction engine also provides two additional fields besides Key and Value: Type and Accuracy.
The Type data provides the nature of the content.In our example above, we can see that the engine recognizes that the Value: esales@orpalis.com is an email, Value: (+33) 6 59 49 60 76 is a phone number, and so on.When the nature of the value is not recognized, you will have Type:String.
The Accuracy data is a confidence level.This confidence level is computed by taking into account many different things, including OCR result at character and word levels, the type of the key, …etc.
We can notice for example in the results that not all accuracies are very high. This is good because it reflects how confident our engine is when extracting information from forms. This gives us the possibility to filter results based on confidence score.
Here is another example with a bank statement:
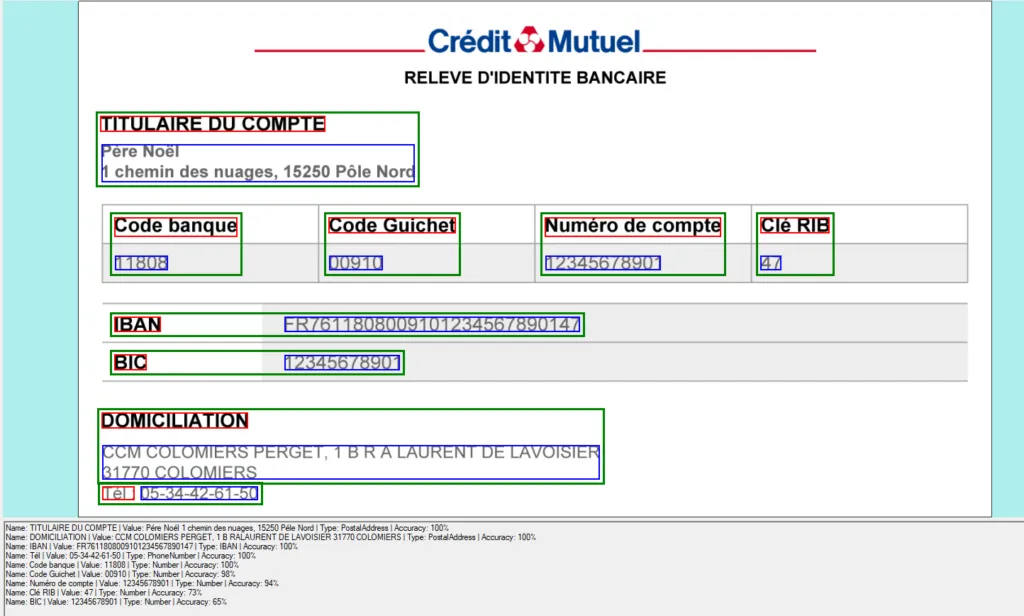
We hope that, like us, you will be excited by all the possibilities that this feature can bring to your applications.Now it’s time to use it!
You will find the KVP engine in the latest version of the SDK(opens in a new tab).
Cheers,
References
[1] Wenwen Yu et al.: ”PICK: Processing Key Information Extraction from Documents using Improved Graph Learning-Convolutional Networks.”
How to Get Started
Integrating GdPicture into your applications is quick and easy. For a customized evaluation and demo, please contact our team of experts(opens in a new tab), and we will guide you properly for your use-case and requirements.
Alternatively, you can also download it for free.(opens in a new tab)


