Deep Learning for OCR
Table of contents

Deep learning OCR improves the accuracy and efficiency of optical character recognition (OCR) by utilizing advanced neural networks. This technology enables better text recognition, even in complex or low-quality documents, enhancing data extraction and automation processes.
OCR or optical character recognition is becoming increasingly important and needed for many companies and organizations that look for ways to automate and streamline their digitalization pipelines. Many companies for example need invoice automation or handwriting recognition. These companies use OCR extensively.
With the rise of AI, we can now tackle OCR problems in an unprecedented way. ORPALIS is at the forefront of developing deep learning-based solutions for solving challenging OCR tasks. We build powerful solutions that help companies and organizations to save resources and become more efficient, fast. Some of these solutions are GdPicture.NET(opens in a new tab), Docuvieware(opens in a new tab), and many more!
Deep learning refers to a field of artificial intelligence that uses neural networks, which is a technique that simulates how the brain processes information. What impact will this have on your organization?
In fact, this new approach that we developed at ORPALIS will handle some edge cases that were very difficult to handle before. Moreover, this approach can be constantly improved, so future versions of our products will continue improving to serve the needs of our customers in the best ways possible.
Components of an OCR engine
1. Introduction:
An OCR engine is composed of 2 parts: text detection and text recognition.
Text detection is the process of finding regions of text in a document. Different documents have different structures (invoice, newspaper, …) so this task has historically been very challenging. Especially as it was done before the deep learning era where engineers were handcrafting features to address such tasks.
On the other hand, a text recognition system takes as input part of a document that contains text (a word or a line of text) and outputs the corresponding text.
Deep learning approaches have shown great potential for both text detection and text recognition.
In this article, we will do a quick introduction to the different deep learning techniques that are used for text detection and text recognition.
In the upcoming articles, we will delve deeper into some of these techniques and we will detail how they work.
2. Text detection using deep learning:
For text detection, many techniques from object detection and instance segmentation have been employed. We will mention some examples in this section.
2.1 Object detection for text detection
Some examples of object detection models being used for text detection include Single Shot Multibox Detection (SSD), Faster-RCNN, and YOLO family.
These are general-purpose techniques for object detection. They are used in a variety of tasks where the goal is to find regions inside an image that contain specific objects (cars, people, …). These same techniques can be applied to solve text detection problems.
Some deep learning techniques that came later used these general-purpose methods and built upon them. One of these techniques is called TextBoxes which was built upon SSD. TextBoxes added long default boxes that have large aspect ratios to SSD, in order to adapt the object detector to text.
Several papers built on this work to make regression-based models resilient to orientations, like the Deep Matching Prior Network (DMPNet) and the Rotation-Sensitive Regression Detector (RRD).
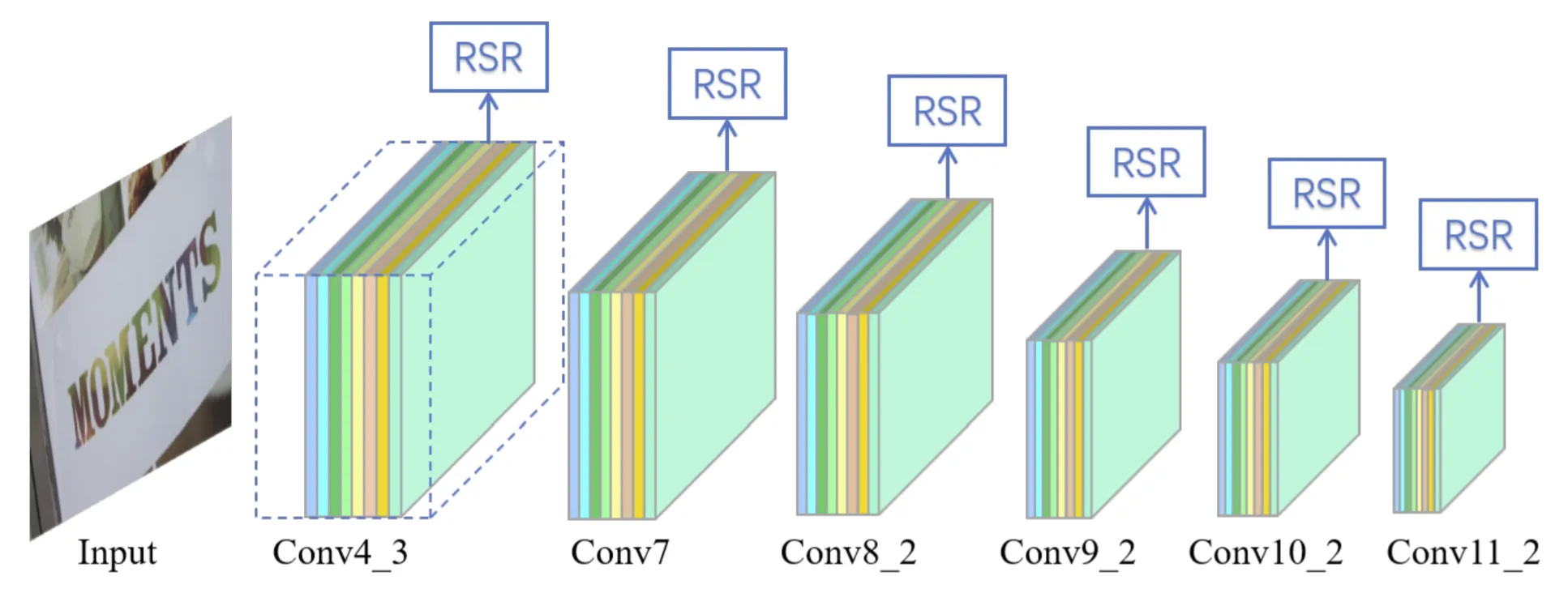
Backbone architecture for RRD [2]
2.2 Instance segmentation for text detection
There are also deep learning techniques from instance segmentation that have been employed for text detection tasks.
Instance segmentation, just like object detection, is a general-purpose deep learning technique. The goal is to find regions that contain specific objects. But these regions are defined at a pixel level.
Some of these techniques are Fully Convolutional Networks (FCN) and TextSnake.
Text detection is always the first part of an OCR engine. The second part is text recognition.
Text recognition using deep learning
When using deep learning for text recognition, there are usually few techniques that have proved effective: recurrent layers and transformers.
Two of the widely used recurrent layers are LSTMs and GRUs.
LSTM stands for Long Short-Term Memory and GRU stands for Gated Recurrent Unit.
Transformers are relatively new in computer vision. They have been employed successfully in NLP (Natural Language Processing) and recently they have shown great potential in computer vision applications.
When LSTMs or GRUs are used in a neural network architecture for text recognition, these networks are called CRNNs (Convolutional Recurrent Neural Networks).
CRNNs are composed of convolutional layers followed by recurrent layers. The goal of convolution is to extract relevant features from images containing the text. Then, recurrent layers together with CTC loss (Connectionist Temporal Classification) are used to turn feature maps into labels corresponding to the text written on the image.
The two parts for text detection and text recognition make a full OCR engine. Sometimes, these parts are fused together in an end-to-end fashion, where the OCR engine takes a full document as an input and outputs text.
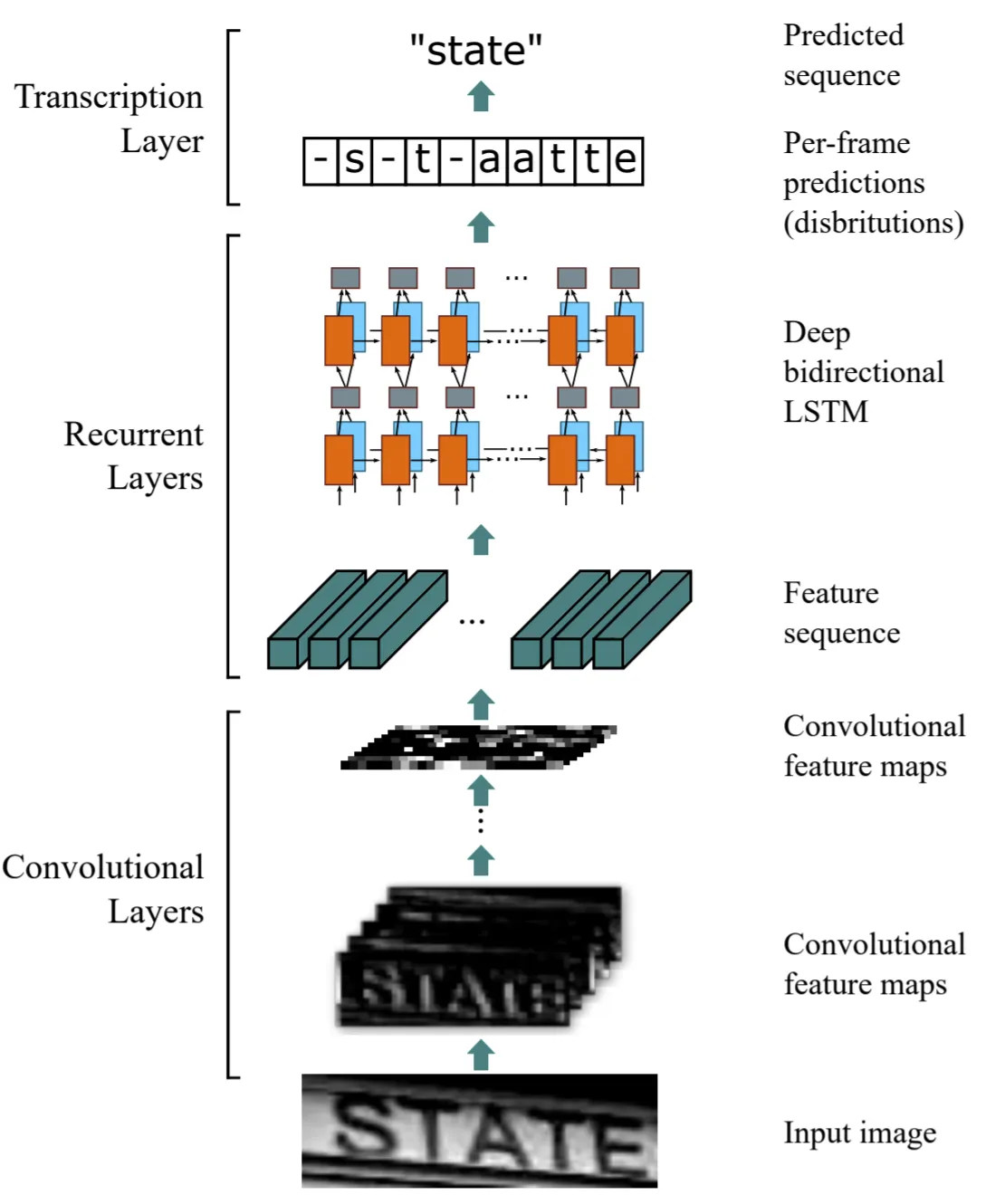
Architecture of CRNN [3]
Conclusion
Deep learning has revolutionized the field of OCR. Just in the last few years, we’ve seen a lot of work being done in this field. Some of the techniques that are used as part of an OCR system have been used in other fields as well. For example, the Faster-RCNN or YOLO family have been very successful in object detection, and now they’ve shown great potential when applied to text detection.
Also, LSTM and Transformer layers have been successfully applied to many NLP related problems and when they are used for OCR they give great results.
This blog article is an introduction to which techniques from deep learning are being used to do OCR. In the upcoming articles, we will detail more different parts of deep learning driven OCR solutions.
Cheers!
References:
[1] Nishant Subramani, Alexandre Matton, Malcolm Greaves, Adrian Lam, “A Survey of Deep Learning Approaches for OCR and Document Understanding”.
[2] Minghui Liao, Zhen Zhu, Baoguang Shi, Gui-song Xia, Xiang Bai, “Rotation-Sensitive Regression for Oriented Scene Text Detection”
[3] Baoguang Shi, Xiang Bai, Cong Yao, “An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition”


